MongoDB数据库
安装
官网 选择合适的版本下载.msi文件安装即可,或者下载解压版本
命令行下运行 MongoDB
为了从命令提示符下运行 MongoDB 服务器,必须从 MongoDB 目录的 bin 目录中执行 mongod.exe 文件,来关联一个文件夹作为数据存储的位置。这里以D盘下的MongoDB为例,文件路径如下:
-D:\Program Files\MongoDB
- data
- db //数据
- log //日志
- Server //Mongodb服务
- 4.0
- bin
- data //系统数据
- log //系统日志
- LICENSE-Community.txt
- MPL-2
- ...关联用户数据文件夹,这里是data下的db,命令如下:
D:\Program Files\MongoDB\Server\4.0\bin\mongod --dbpath D:\Program Files\MongoDB\data\db配置mongod命令到系统的环境变量中,将D:\Program Files\MongoDB\Server\4.0\bin\加入到 控制面板->系统与安全->系统->高级系统设置->环境变量->系统变量->Path 中即可。再次打开命令行输入mongo命令出现版本号和信息即成功。
C:\Users\17879> mongo
MongoDB shell version v4.0.8
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("2e4226ab-6fff-4fc1-bba0-baf52c6f2f33") }
MongoDB server version: 4.0.8
> 设置批处理文件来启动或者使用Mongoliandb的MongoDB Compass Community可视化工具。其默认的端口号是27017.
mongo.exe --dbpath=D:\Program Files\MongoDB\data\db连接MongoDB
可以在命令窗口中运行 mongo 命令即可连接上 MongoDB,执行如下命令:
C:\Users\17879>mongo如果需要查看合适的options可以使用命令:
C:\Users\17879>mongod -help体系结构概念
mongodb与SQL术语的概念对比:
数据库 database
在一个mongodb中可以建立多个数据库(母庸置疑),默认数据库为db,放在data目录中。mongoDB的单个实例可以容纳多个数据库,不同的数据库也可以放置在不同的文件中。展示所有数据库列表使用命令 show dbs(前提是已经连接了MongoDB,参见上节)。
C:\Users\17879>show dbs这里还有一些其他命令:
- 使用db命令可以展示当前所使用的数据库名称;
- 使用use database可以切换连接到一个指定的数据库中。
数据库的名称命名和JAVA中的关键字差不多,原则是:非空,不含有空格,英文句号,美元符号,左右划线,应该全部小写,最多64字节。其中有一些数据库的名称是保留的,例如
admin(root数据库,权限控制,一些特定命令只能从这个数据库运行),
local(存储仅限于本地单台服务器的任意集合,不可复制),
config(mongo用于分片设置时在内部使用保存分片信息)。
文档 document
文档本质上是一组键值对(BSON)。MongoDB的文档组织相当的松散,相同的字段不需要相同的数据类型(关系型数据库中是不成立的)。可以在程序中动态定义文档的结构,也可以自定义文档结构。document相当于数据库表中的一行记录。
集合 collection
集合是文档组,类似于RDBMS中的表 table。注:RDBMS- relational database management system.
集合存在数据库中,可以将不同的数据结构插入到集合之中。当第一个文档被插入时,集合就会被创建。一般不要使用特殊字符作为集合名称,会和系统保留前缀或名称冲突。
三者关系
一个mongodb server支持多个数据库,每个db中包含多个collection,每个collection由多个document组成。
数据类型
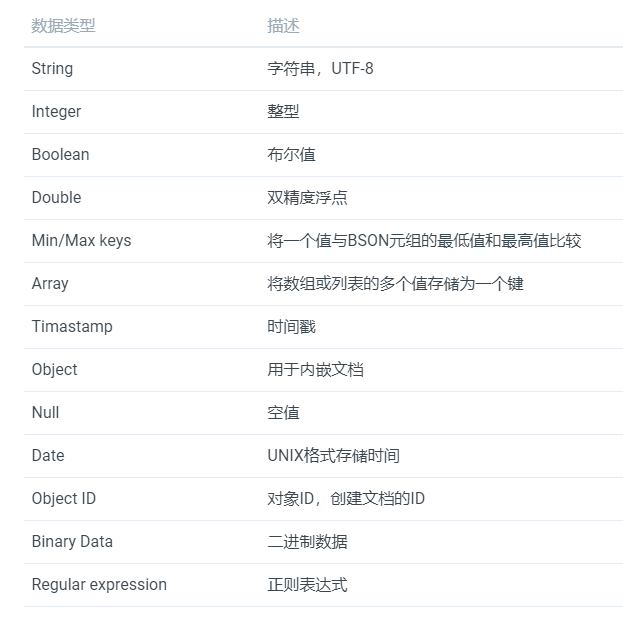
基本数据操作
为了使用方便,也可以为mongodb设置客户端。
mongo.exe 127.0.0.1:27017/admin连接后的help帮助文档
db.help() help on db methods
db.mycoll.help() help on collection methods
sh.help() sharding helpers
rs.help() replica set helpers
help admin administrative help
help connect connecting to a db help
help keys key shortcuts
help misc misc things to know
help mr mapreduce
show dbs 查看所有数据库
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
show logs show the accessible logger names
show log [name] prints out the last segment of log in memory, 'global' is default
use <db_name> 创建或者切换到目标数据库。注意:如果创建空的数据库(未添加集合和文档)离开后会自动销毁。如果是已经存在的数据库,就自动切换到目标数据库。
db.foo.find() list objects in collection foo
db.foo.find( { a : 1 } ) list objects in foo where a == 1
it result of the last line evaluated; use to further iterate
DBQuery.shellBatchSize = x set default number of items to display on shell
exit quit the mongo shelldb.[collectionName].insert( {…} )
向指定数据库添加集合并且添加记录,insert的参数可以是BSON格式或者对象名。
> use nodedb
switched to db nodedb
> show collections
users
> person={"name":"yanbo01haomiao"}
{ "name" : "yanbo01haomiao" }
> animal={"name":"cat"}
{ "name" : "cat" }
> db.persons.insert(person)
WriteResult({ "nInserted" : 1 })
> db.persons.insert(animal)
WriteResult({ "nInserted" : 1 })
> show collections
persons
usersdb.[collectionName].find()
> db.persons.find()
{ "_id" : ObjectId("5d196e0bc9827fb3a4e9aa90"), "name" : "yanbo01haomiao" }
{ "_id" : ObjectId("5d196e13c9827fb3a4e9aa91"), "name" : "cat" }相当于关系型数据库中select * from table.其中_id为Objectid。
Objectid
mongodb支持的数据类型中,ObjectId是其自有产物。存储在mongodb集合中的每个文档(document)都有一个默认的主键_id,这个主键名称是固定的,它可以是mongodb支持的任何数据类型,默认是ObjectId,可以很快的生成和排序。
ObjectId的12字节是如此构成的:0-3这4个字节是时间戳(timestamp)、4-6这3个字节是机器码(machine)、7-8这2个字节是进程id(pid)、9-11这3个字节是程序自增id(increment)。
- 前4字节表示船舰unix时间戳,时间为格林尼治时间UTC。因为ObjectId以时间戳打头,所以它是近似有序的,使得_id的索引插入效率相比普通索引高很多
- 接下来3字节为机器标识码
- 接下来2字节为进程id组成的PID
- 最后3字节为随机数计数器
ObjectId的前9个字节(timestamp+machine+pid)可以保证不同进程生成的ObjectId不会重复,而后3个字节increment又可以保证同一进程内生成的ObjectId不会重复,所以无需怀疑ObjectId的全局唯一性。
ObjectId存储是12个字节,但如果应用有需要以可读的方式表现它,就需要将它转成字符串,这需要24字节(每字节转成2字节的16进制表示),这个长度的字符串看起来就有些不让人舒服了,如果是追踪某个id引发的bug,就需要配上copy+paste的杀招。
在关系数据库schema设计中,主键大多是数值型的,比如常用的int和long,并且更通常的,主键的取值由数据库自增 获得,这种主键数值的有序性有时也表明了某种逻辑。
反观mongodb,它在设计之初就定位于分布式存储系统,所以它原生的不支持自增主键。
ObjectId被设计成跨机器的分布式环境中全局唯一的类型,长度是12个字节。字节长度比int大了两倍,比long也多了一个int,但在现在的硬件配置中,多出的这些字节很难有理由成为限制系统的瓶颈所在,所以尽可放心使用。
::tip
初涉ObjectId很容易犯的两个错误:
查询时直接使用类似db.collection.find({_id:”xx”})式的代码, 结果怎么也查不到明明存在的文档,而正确的写法应该是:db.collection.find({_id:new ObjectId(“xx”)})。
集合间有外键关联时,也需要将外键置为ObjectId类型,而不要直接使用上24字节的string。在写与 mongodb打交道的CRUD代码时,需要多留意ObjectId和string的转换代码。
::
db.[collectionName].findOne()
查询集合中的第一条数据,这个语句的使用很又意义,类似于找到关系型数据库条件查询的返回数据的第一条。
db.[collectionName].update( {查询条件}, {更新内容})
> db.persons.update(db.persons.findOne(),{"name":"yanbo"})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.persons.find()
{ "_id" : ObjectId("5d196e0bc9827fb3a4e9aa90"), "name" : "yanbo" }
{ "_id" : ObjectId("5d196e13c9827fb3a4e9aa91"), "name" : "cat" }db.[collectionName].remove( {…} )
删除文档数据
增删
批量插入文档
shell不支持批量插入,需要进行修改,可以使用for循环,mongoDB是基于js的语法。
> for(var i=0;i<5;i++){
... db.persons.insert({"name":i});
... }
WriteResult({ "nInserted" : 1 })
> db.persons.find()
{ "_id" : ObjectId("5d196e0bc9827fb3a4e9aa90"), "name" : "yanbo" }
{ "_id" : ObjectId("5d196e13c9827fb3a4e9aa91"), "name" : "cat" }
{ "_id" : ObjectId("5d19756cc9827fb3a4e9aa92"), "name" : 0 }
{ "_id" : ObjectId("5d19756cc9827fb3a4e9aa93"), "name" : 1 }
{ "_id" : ObjectId("5d19756cc9827fb3a4e9aa94"), "name" : 2 }
{ "_id" : ObjectId("5d19756cc9827fb3a4e9aa95"), "name" : 3 }
{ "_id" : ObjectId("5d19756cc9827fb3a4e9aa96"), "name" : 4 }save操作
如果在insert插入时_id已经存在(一般时人为设定_id时会重复,使用系统默认生成的_id则不会重复),会出现错误,因为主键不允许重复。
无法判断这样的情况时使用save命令,当遇到_id相同时save会自动完成修改操作,避免了insert的报错。
删除 db.[collectionName].remove( {…} )
db.[collectionName].remove( {…} )是删除指定文档数据,如果去掉条件就是删除集合中全部文档,但是集合本身和索引不会被删除。
修改/更新 db.[collectionName].update( {查询条件}, {更新内容})
db.[collectionName].update( {查询条件}, {更新内容})中的更新内容中可以加入$set:{ field: value }修改器用于增加新的字段。如果不写修改器则默认为更改field操作。
> db.persons.update(db.persons.findOne(),{$set:{"age":"22"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.persons.find()
{ "_id" : ObjectId("5d196e0bc9827fb3a4e9aa90"), "name" : "yanbo", "age" : "22" }Select 查询
先插入模拟数据。
db.persons.drop()
var personArr = [{
name: "zhangsan",
age: 22,
email: "1787948156@qq.com",
c : 89, m : 78, e : 99,
contry: "China",
books: ["JS", "JAVA", "MongoDB"]
}, {
name: "lichong",
age: 23,
email: "1784512477@qq.com",
c : 80, m : 82, e : 93,
contry: "Japan",
books: ["JS", "PHP", "MongoDB"]
}, {
name: "lishuhuan",
age: 22,
email: "17161515@qq.com",
c : 75, m : 98, e : 100,
contry: "china",
books: ["Vue", "JAVA", "MongoDB"]
}, {
name: "songhuan",
age: 21,
email: "65871558@qq.com",
c : 98, m : 87, e : 93,
contry: "USA",
books: ["MySQL", "JAVA", "MongoDB"]
}, {
name: "wuyong",
age: 22,
email: "1568457953@qq.com",
c : 84, m : 78, e : 99,
contry: "Korea",
books: ["C++", "JAVA", "C"]
}]
for (var i=0; i<personArr.length; i++){
db.persons.insert(personArr[i])
}查询部分字段
查询persons表中的name,age,contry字段
> db.persons.find({},{_id:0,name:1,age:1,contry:1})
{ "name" : "zhangsan", "age" : 22, "contry" : "China" }
{ "name" : "lichong", "age" : 23, "contry" : "Japan" }
{ "name" : "lishuhuan", "age" : 22, "contry" : "china" }
{ "name" : "songhuan", "age" : 21, "contry" : "USA" }
{ "name" : "wuyong", "age" : 22, "contry" : "Korea" }db.collection.find( {条件}, {键指定}),在这里第一个参数条件可以不书写,表示空对象,表示全部查询,第二个参数表示要查询谁就设置谁为1,否则设置为0,_id默认会查询出来,当然也可以指定_id:0不查询。

查询年龄在21-22之间的学生的name,age
> db.persons.find({age:{$gte:21,$lte:22}},{_id:0,name:1,age:1})
{ "name" : "zhangsan", "age" : 22 }
{ "name" : "lishuhuan", "age" : 22 }
{ "name" : "songhuan", "age" : 21 }
{ "name" : "wuyong", "age" : 22 }查询条件
$in 包含
$nin 不包含
关于包含与不包含的关系,后面需要跟数组。
查询国籍是中国或美国的学生的姓名,国籍,年龄
> db.persons.find({contry:{$in:["USA","china","China"]}},{_id:0,name:1,contry:1,age:1})
{ "name" : "zhangsan", "age" : 22, "contry" : "China" }
{ "name" : "lishuhuan", "age" : 22, "contry" : "china" }
{ "name" : "songhuan", "age" : 21, "contry" : "USA" }find带条件类似于SQL中的where待条件查询
db.persons.find({"age":21})
==> select * from persons where age=21
db.persons.find({"age":21,"name":"songhuan"}, {name:1,age:1,contry:1,_id:0})
==> select name,age,contry from persons where age=21 and name='songhuan'多表查询
实现方案一般有两种:嵌套和引用。
嵌套
一对多中进行嵌套,关系型数据是抽取主键进行关联。
> var classes = {
... id:1,
... name:"JAVA",
... students:[{
... sid:1,
... name:"zhangsan"
... },{
... sid:2,
... name:"lisi"
... }]
... };
> db.classes.insert(classes);
WriteResult({ "nInserted" : 1 })
> db.classes.find()
{ "_id" : ObjectId("5d19be7cc9827fb3a4e9aa9c"), "id" : 1, "name" : "JAVA",
"students" : [ { "sid" : 1, "name" : "zhangsan" }, { "sid" : 2, "name" : "lisi" } ] }查询班级为JAVA的班级的第一个学生的sid
> db.classes.find({"name":"JAVA"}).forEach(function(e){printjson(e.students[0].sid)})
1查询id为1的班级中的所有学生
> db.classes.find({"id":1},{"students":1,"_id":0})
{ "students":[{ "sid" : 1, "name" : "zhangsan" }, { "sid" : 2, "name" : "lisi" } ] }嵌套数据保存在一个单一文档中,比较容易获得和维护数据,但是数据量的不断增加,会影响读写性能。
需要注意的是在findOne返回数据类型是一个对象,find返回的数据类型是数组
引用
引用式关系是设计数据库时经常用到的方法,这种方法把用户数据文档和用户地址数据文档分开,通过引用文档的 id 字段来建立关系。这种方法需要两次查询,但是数据相互分离。



